- Yujie Zhao
- Lanxiang Hu
- Zhijing Wu
- Junbo Huang
- Zhongming Yu

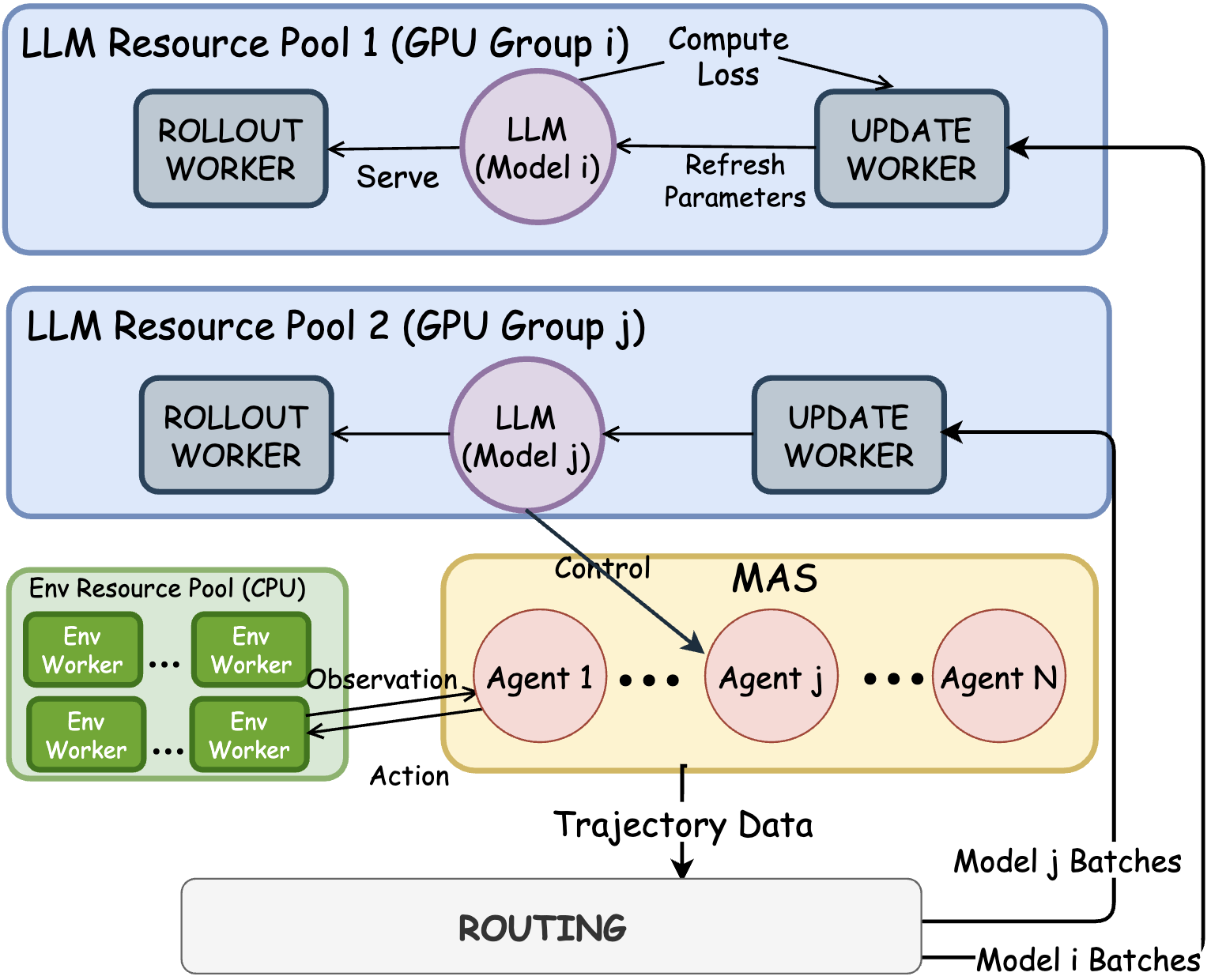
Multi-Agent System (MAS) and Reinforcement Learning (RL) are both widely adopted to improve large language model (LLM) agentic performance. MAS strengthens task-specialized performance via role-based orchestration; RL leverages environment rewards to train stronger policies, such as Group Relative Policy Optimization (GRPO)-style optimization. Yet applying on-policy RL training to MAS is underexplored. While promising, it poses several challenges. On the algorithm side, Standard GRPO grouping assumptions fail in MAS because prompts differ by role and turn. On the system side, the training system needs to support MAS-workflow-based rollouts and on-policy updates for both single and multiple policy models. To address these issues, we introduce AT-GRPO, consisting of (i) an Agent- and Turn-wise grouped RL algorithm tailored for MAS and (ii) a system to support both single-policy and multi-policy training. Across game, plan, coding, and math tasks, AT-GRPO demonstrates substantial performance gains across diverse domains. Especially on long-horizon planning tasks, AT-GRPO boosts accuracy from a 14.0–47.0% single-agent RL baseline to 96.0–99.5%. Furthermore, it improves reasoning performance, with an average gain of 3.87–7.62% on coding and 9.0-17.93% on math.

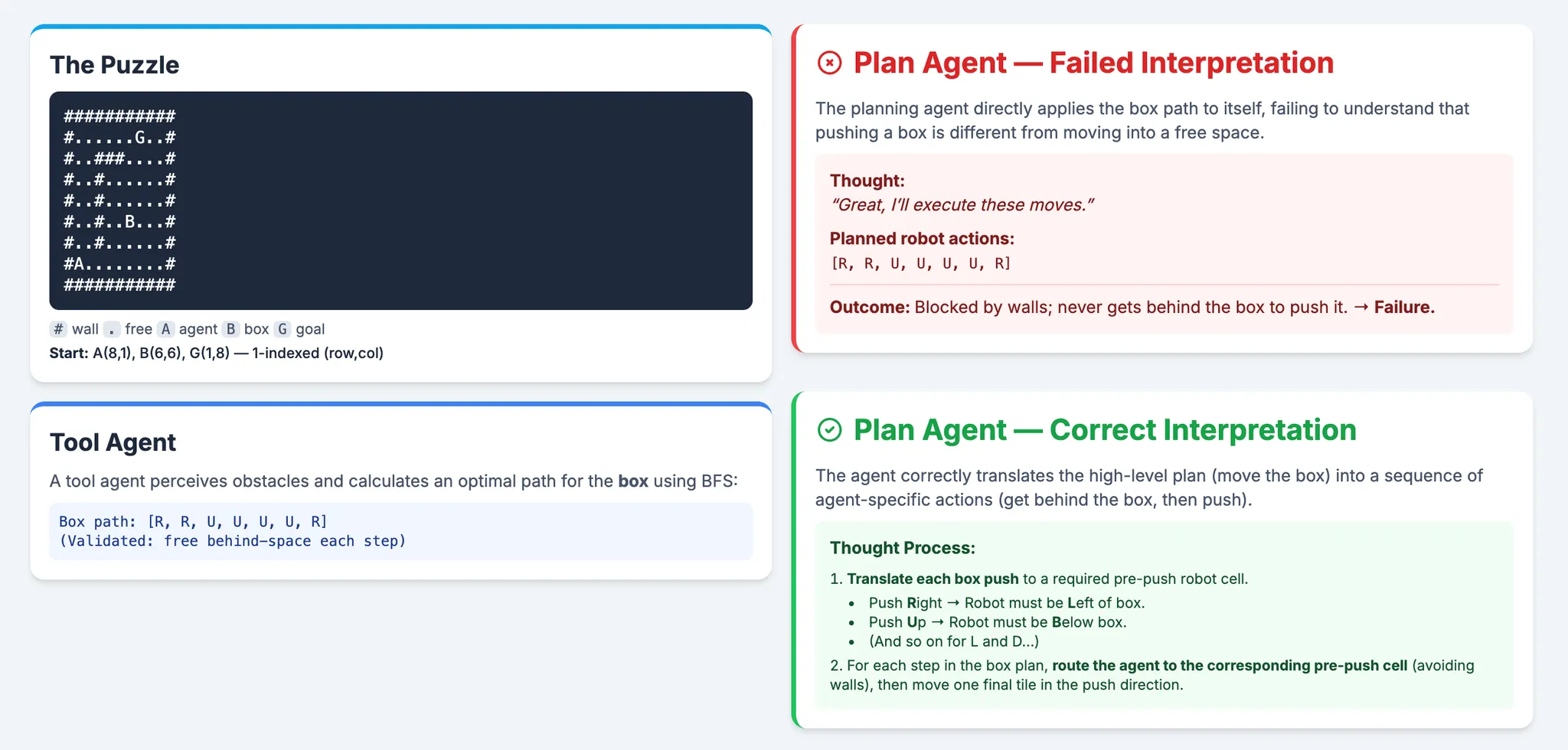
Task: Planner proposes the next action sequence; Executor calls environment tools (simulator, legality checker, shortest-path/BFS helper) to apply actions and return effects/observations (updated grid, agent/box poses, success/failure flags). Episode ends when the goal is met (all boxes on targets) or the turn budget is reached.
Before RL: The Plan Agent gets a valid path for the box from Tool agent but completely misses the point. It tries to follow the box's path itself, runs straight into a wall, and fails instantly. It doesn't understand its job is to push the box, not be the box.
After on-policy RL in MAS: RL teaches the agent the difference. It learns that rewards come from moving the box along the designated path. This insight forces it to discover the correct low-level strategy: first, navigate behind the box, then execute the push
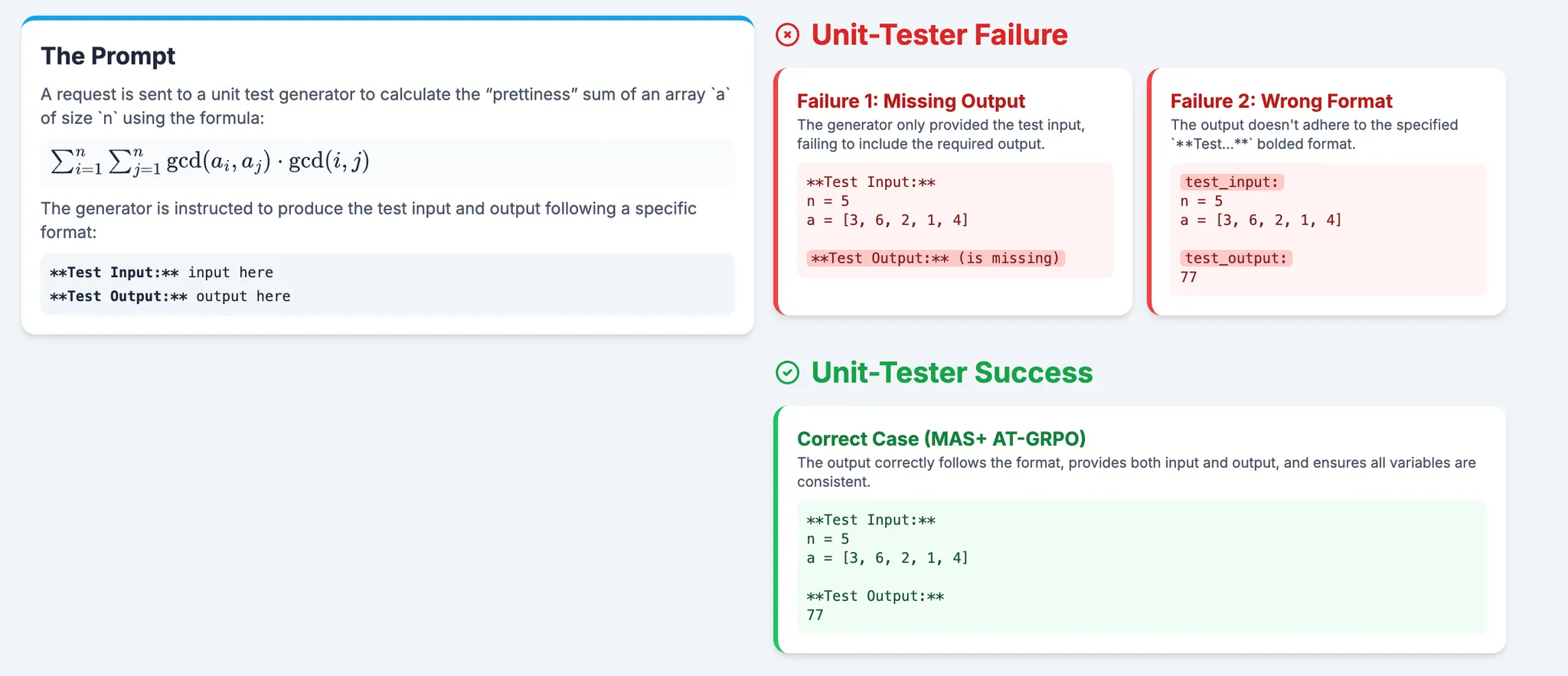
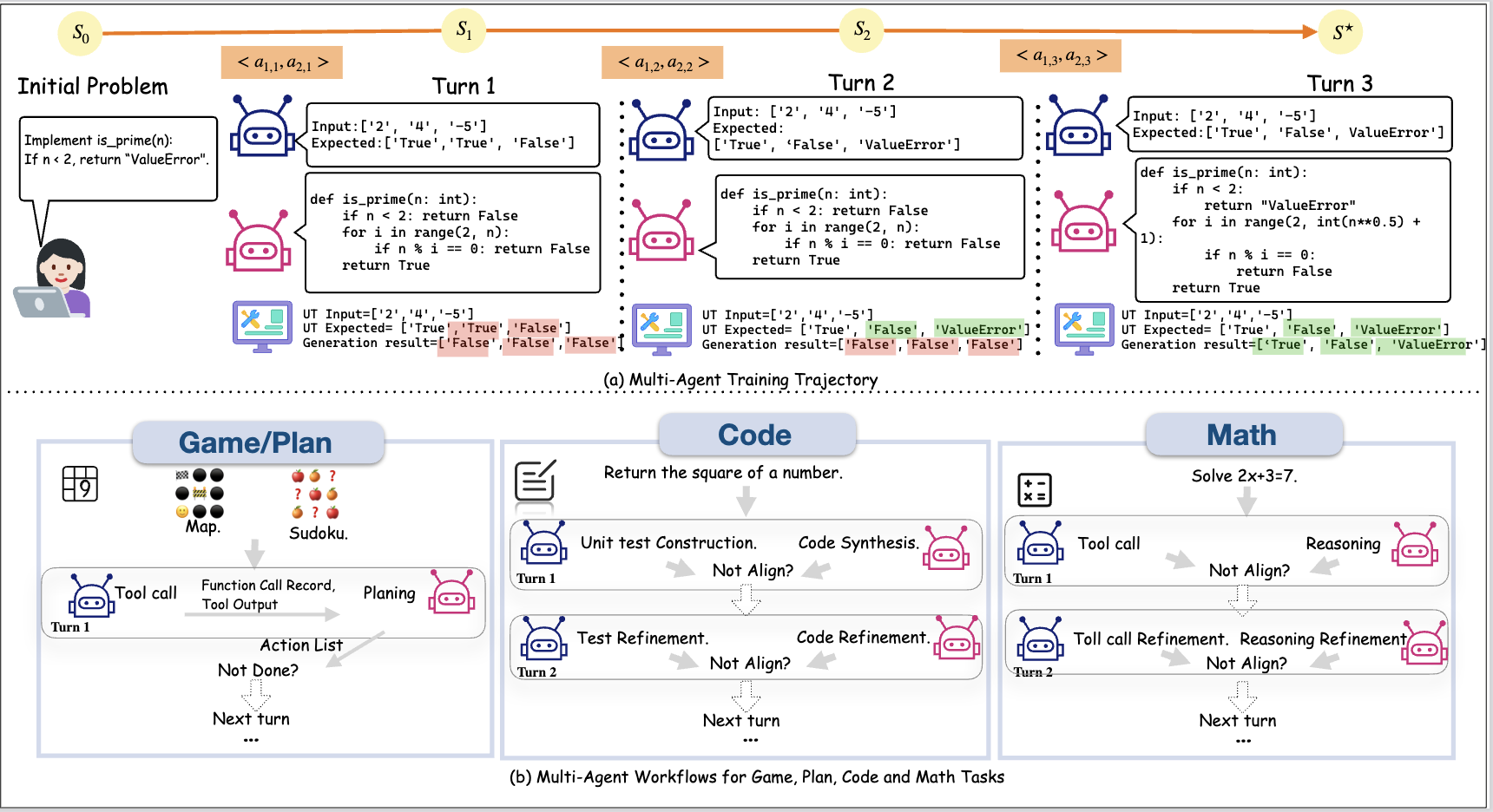
Task: Coder writes a solution; Unit-Tester writes tests. Terminate=all tests pass. Otherwise: each agent revises its own previous output using the environment feedback/results (Coder fixes code; Unit-Tester fixes unit test), then re-run.
Before RL: The Plan Agent gets a valid path for the box from Tool agent but completely misses the point. It tries to follow the box's path itself, runs straight into a wall, and fails instantly. It doesn't understand its job is to push the box, not be the box.
After on-policy RL in MAS: RL teaches the agent the difference. It learns that rewards come from moving the box along the designated path. This insight forces it to discover the correct low-level strategy: first, navigate behind the box, then execute the push.
Affiliation: Department of Computer Science and Engineering, UC San Diego
